Find possible duplicate indexes
Want to locate possible duplicate / redundant indexes?
Cl
Claus Munch
Jan 28, 2026 · 1 min read
234 views
A team sent me on a little quest, "do we have any redundant indexes?".. Well, this is a t-sql script locating potential candidates for that exact title :)
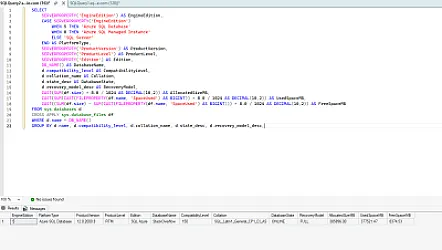
;WITH IndexColumns AS (
SELECT
i.object_id,
OBJECT_SCHEMA_NAME(i.object_id) AS SchemaName,
OBJECT_NAME(i.object_id) AS TableName,
i.index_id,
i.name AS IndexName,
i.type_desc AS IndexType,
STUFF((
SELECT ',' + c.name + CASE WHEN ic.is_descending_key = 1 THEN '(-)' ELSE '(+)' END
FROM sys.index_columns ic
INNER JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 0
ORDER BY ic.key_ordinal
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)'), 1, 1, '') AS KeyColumns,
STUFF((
SELECT ',' + c.name
FROM sys.index_columns ic
INNER JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 1
ORDER BY c.name
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)'), 1, 1, '') AS IncludedColumns,
(ps.used_page_count * 8.0) / 1048576.0 AS IndexSizeGB,
ISNULL(ius.user_seeks, 0) + ISNULL(ius.user_scans, 0) + ISNULL(ius.user_lookups, 0) AS TotalReads,
ISNULL(ius.user_updates, 0) AS UserUpdates
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats ps
ON i.object_id = ps.object_id AND i.index_id = ps.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius
ON i.object_id = ius.object_id
AND i.index_id = ius.index_id
AND ius.database_id = DB_ID()
WHERE i.type_desc IN ('CLUSTERED', 'NONCLUSTERED')
AND i.is_hypothetical = 0
AND OBJECTPROPERTY(i.object_id, 'IsMsShipped') = 0
)
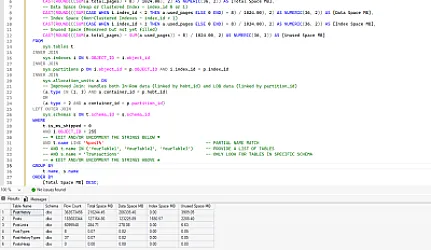
SELECT
ic1.SchemaName,
ic1.TableName,
ic1.IndexName AS RedundantIndex,
ic1.IndexSizeGB AS RedundantSizeGB,
ic1.TotalReads AS RedundantReads,
ic1.UserUpdates AS RedundantUpdates,
ic2.IndexName AS CoveringIndex,
ic2.IndexSizeGB AS CoveringSizeGB,
ic2.TotalReads AS CoveringReads,
ic2.UserUpdates AS CoveringUpdates,
CASE
WHEN ic1.KeyColumns = ic2.KeyColumns THEN 'EXACT DUPLICATE'
WHEN ic2.KeyColumns LIKE ic1.KeyColumns + ',%' THEN 'COVERED BY (prefix match)'
ELSE 'POTENTIAL DUPLICATE'
END AS RedundancyType,
ic1.KeyColumns AS RedundantKeyColumns,
ic2.KeyColumns AS CoveringKeyColumns,
ic1.IncludedColumns AS RedundantIncludes,
ic2.IncludedColumns AS CoveringIncludes
FROM IndexColumns ic1
INNER JOIN IndexColumns ic2
ON ic1.object_id = ic2.object_id
AND ic1.index_id <> ic2.index_id
AND (
ic1.KeyColumns = ic2.KeyColumns -- Exact duplicate
OR
ic2.KeyColumns LIKE ic1.KeyColumns + ',%' -- ic2 has MORE columns (covers ic1)
)
WHERE ic1.IndexType = 'NONCLUSTERED'
ORDER BY
ic1.SchemaName,
ic1.TableName,
ic1.IndexSizeGB DESC;